
正文:
这里分享两个原创的python小工具,本来是发到t00ls的,新人想赚点积分提升阅读权限,但是被人踩了,对那边的环境和规矩一言难尽,让人很不爽,已经申请销号处理了。
| 脚本 | 功能 |
|---|---|
| fofa_search.py | 通过fafa批量爬取检索结果 |
| WebFinder.py | 获取存活的WEB URL以及对应的标题 |
fofa_search
该脚本通过多线程爬取搜索页面的链接信息,输入参数为网页登录后的cookie信息,可通过浏览器F12 查看网络连接复制获取,支持主机和web查询,在对目标组织进行渗透的时候可以使用该脚本检索目标主机存在weblogic\struts2\tomcat\致远OA等组件的主机,然后结合poc-t\pocsuite\pocstart等漏洞检测框架批量检测,运气好的话很容易就能拿到webshell.
Usage: fofa_search.py -c cookie -q dork [-n pages -t thread_num -o save_result.txt
Options:
--version show program's version number and exit
-h, --help show this help message and exit
-c COOKIE, --cookie=COOKIE
Insert cookie after login fofa
-q DORK, --dork=DORK Insert fofa query dork
-n LIMIT, --limit=LIMIT
set search page numbers:defalut:20
-s TYPE, --type=TYPE set search search type.[www|host] default:www
-t THREADS, --threads=THREADS
Insert query all pages:defalut:20
-o OUTFILE, --outfile=OUTFILE
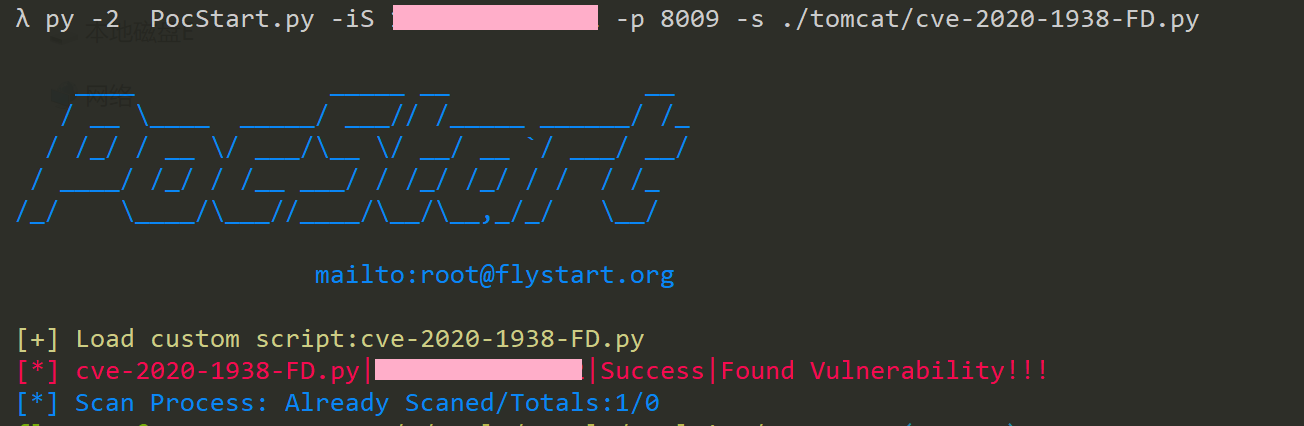
Insert save filename. defualt:fofa_result.txt以下对目标组织检索tomcat主机检索然后利用pocstart批量检测并发现文件下载漏洞。
fofa dork:org="XXX Limited" && region="CN" && protocol=="ajp"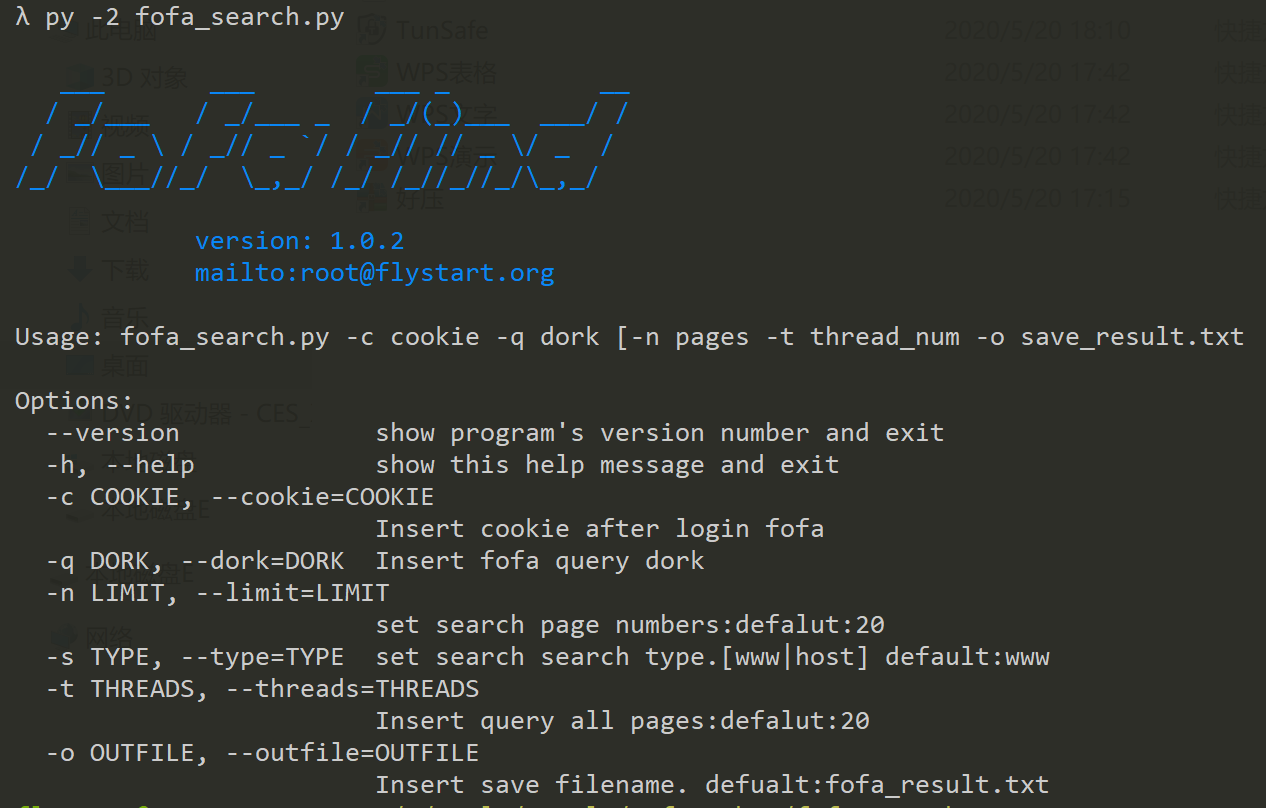
核心代码:
def fofa_query(all_pages,dork):
global search_type
ret = ""
url = "https://fofa.so/result?"
qbase = base64.b64encode(dork)
for i in range(1,all_pages+1):
params = {"page":str(i),"qbase64":qbase}
try:
res = req.get(url,params= params,headers=headers)
text = res.content
if search_type =='www':
get_www_result(text)
if search_type == 'host':
get_host_result(text)
except Exception,e:
print e.message
return
def get_www_result(html):
global outfile
try:
soup = BeautifulSoup(html, 'html.parser')
div = soup.find_all('div', attrs={'class': 'list_mod_t'})
_soup = BeautifulSoup(str(div), 'html.parser')
a= _soup.find_all('a', attrs={'target': '_blank'})
for v in a:
url = v['href']
print url
put_file_contents(outfile,url)
except Exception,e:
print(e.message)
return
def get_host_result(html):
global outfile
try:
soup = BeautifulSoup(html, 'html.parser')
div = soup.find_all('div', attrs={'class': 'list_mod_t'})
_soup = BeautifulSoup(str(div), 'html.parser')
a = _soup.find_all('div', attrs={'class': 'ip-no-url'})
if a:
for host in a:
host = (host.string).replace(r'\n','').strip()
print(host)
put_file_contents(outfile,host)
except Exception,e:
print(e.message)
returnWebFinder
该脚本主要是为了检索目标组织存活的web host以及对应的web标题,通过标题信息粗略定位下一步渗透的目标系统,通常用于内网渗透过程的信息收集,对于只能通过webshell 操作的目标,可以使用pyinstaller打包上传到目标机器进行内网信息收集,然后利用regeorg代理渗透内网。附件也提供了一个打包好的exe。
Usage: WebFinder.py -u URL [-f urls.txt]
Options:
-h, --help show this help message and exit
-u URL, --url=URL Insert TARGET URL: http[s]://www.victim.com[:PORT]
-t THREADS, --threads=THREADS
set scan thread number
-F INFILE, --infile=INFILE
Insert domain filename ::
-m ACTION, --action=ACTION
set function options [get_www,get_title] ::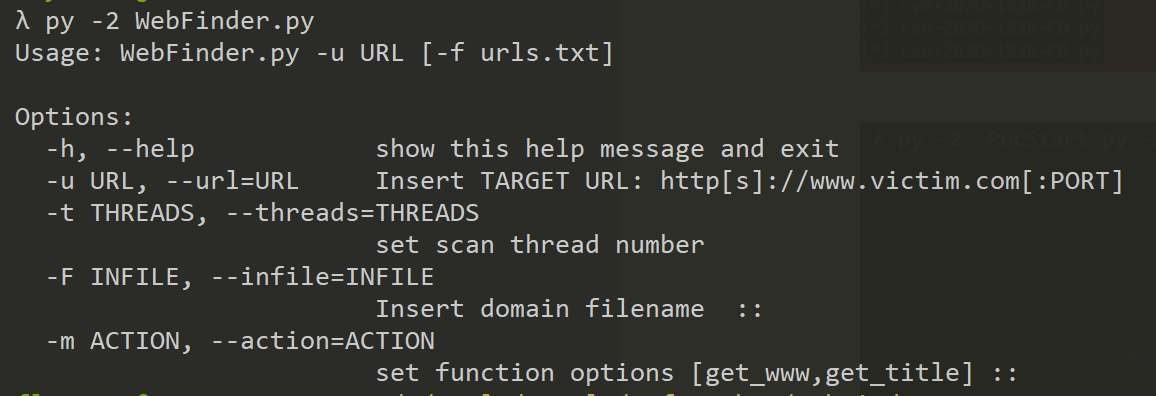
核心代码:
def find_www(url):
found_url = ""
con_url = check_url(url)
try:
status_code, head, content, redirect, log = hh.http(con_url, headers=headers, timeout=5)
if status_code == 200:
found_url = con_url
else:
con_url = check_url(url,True)
status_code, head, content, redirect, log = hh.http(con_url, headers=headers, timeout=5)
if status_code == 200:
found_url = con_url
except Exception as e:
print e.message
if found_url:
print("FoundWWW:%s"% found_url)
return found_url
def get_info(url):
banner = ""
try:
status_code, head, content, redirect, log=hh.http(url,headers=headers,timeout=5)
temp = head.strip('\r\n').split('\r\n')
header = dict([s.split(':',1) for s in temp])
status = status_code
title = "None"
data = content
title = re.search(r'<title>(.*?)</title>', data) # get the title
try:
if title:
title = title.group(1).encode('utf-8').decode('utf-8').strip().strip("\r").strip("\n")[:30]
else:
title = "None"
except Exception,e:
pass
banner = "%s||%s||%s||"%(url,status,title)
if header['Server']:
banner += header['Server'] #get the server banner
elif headers['X-Powered-By']:
banner += header['X-Powered-By']
print banner
except Exception,e:
print e.message
return banner声明:本站大部分下载资源收集于网络,只做学习和交流使用,版权归原作者所有,未及时购买和付费发生的侵权行为,与本站无关。


niuniu
scan.exe 工具的下载链接失效了。
?没有失效哦!
终于找到了 感谢分享
感谢分享