

对于用户来说,抖音账号的标注只是为了让你上瘾。你喜欢漂亮的小姐姐,刷得越多,系统就越会推荐给你。如果你喜欢烹饪,系统会向你推荐好吃的视频,这些都源于抖音的标签功能。

对于创作者来说,标签提供了操作上的便利,因为你的最终目的无非是养粉,当你发送作品时,系统会根据你的作品类型给你的作品贴上标签,推荐给其他喜欢你类型的用户,大大提高了效率。
你的账号内容越垂直,越容易被系统标记和推荐。
什么是“垂直内容”标签?
记住,重点放在关键词上,比如育儿、情感、情商、职场、办公室、励志。就像古代的家谱一样,每个领域都有自己的标签。
比如情商领域的标签有口才、职场、销售。
儿童保健领域的标签包括儿童饮食、母亲和婴儿、家庭作业等。
职场上的标签是老板、员工、上班等。
对于创作者来说,如何按照算法机制准确标注?
第一步:精确定位
如果你的初始定位不准,不知道该怎么做,做了一个乱数,那么你的账号基本上很难或者很慢被系统标记,所以一开始一定要有最好的垂直定位。
第二步:提高数量
关于留号有很多不同的看法。对贴标签有用吗?做过抖音的老司机都知道有些效果。事实上,这是毛毛雨效应。
当你的视频爆炸的时候真的很有用。(就像你家以前穷,卑微,抬不起头。在你出人头地,赚到500万之前,它在村子里是一个透明的存在。这时,你出去倒垃圾,有人蹲下来求救。社会很现实,抖音也很现实。)
如果你是新手,真的很慌,那就养两三天。
第三步:连续输出
当你定位好了,继续输出,既方便系统准确标注你,也让粉丝信任你。相比之下,后者更重要。
很多朋友问,如何判断你的账号是否有标签?
就用这个招数:
你用小号来关注你正在做的抖音,在“取消关注”按钮的右边有一个箭头,会推荐可能感兴趣的人。
这也是为什么不建议经常换视频风格的原因。即使成了爆款视频,也只能带来一次势能,给后面的抖音操作带来不必要的难度。
抖音标签有什么作用?
万变不离其宗,标签的作用只有一个:尽可能把你的作品分发给有相应需求的用户。给你加粉,让你引流实现。最后,如何利用抖音标签功能获得精准的粉丝?
具体操作:
a .可以打标签的地方
- (1)封面打标签
- (2)文案打标签
- (3)内容打标签
- (4)声音打标签
- (5)昵称打标签
- (6)个签打标签
b .标签越多收获的用户就越精准
比如说你的客户是石家庄桥西区羽绒服,定位地区客户的一个关键词,如果同时触发了石家庄,羽绒服,就会获得该抖音标签下的精准推荐。
c .标签万能公式
标签万能公式,地区范围关键词+精准关键词+拓展关键词=你的精准潜在客户的关键词。
通过在封面、视频标题、视频内容、个性签名等地方插入关键词,这样一个完整“标签”视频就出来了。用户可以通过搜索关键词搜索到你的视频,更重要的是,标签越精准,视频触动的用户也越精准,根据抖音独特的推荐算法,成为爆款视频也就是上热门的几率更高。
微信抖音是怎么给我们打标签的?
微信抖音的用户画像沉淀方法
画像,本质上就是给账号、设备等打标签。
用户画像 = 打标签
一、设备标签
首先查看APP列表
一个设备首先有没有违规的APP(大部分的灰黑产从业者都在保证批量化运营的时候会安装一些自动化脚本及恶意APP)是否有常用APP(觉得大多灰黑产在追求效率)
以抖音为例
标签的类别和明细,,比如:陀螺仪,内存,用电量,通讯录 指纹 手机卡等等。其他细致规则以此规律自己去设定。
抖音的设备画像,沉淀的逻辑如下:
一般的业务都有针对设备的激活时长、次数限制的策略,那么黑产为了对抗,模拟大量的设备数据与设备农场
设备在风控领域是非常重要的一环。
风控行业对设备的定义就是指用户与业务系统的一个载体
我们对每一台设备生成一个唯一且稳定的标识称为设备ID。
设备指纹的原理就是收集客户端的特征属性信息通过算法分析来给每一台设备进行标记、
手机操作系统与浏览器厂商为了方便开发者获取用户信息,会预留一下API给程序使用,用户与开发者通过这些API获取客户端相关的软硬件信息,当然这些信息每个设备也是不同的,设备指纹就是通过部分的差异信息开做一套自己的完全独立的设备ID,当然还有其他可参考内容。(切记用户通讯录 短信 手机号 通话记录等是不能作为生成设备ID的 ,只能校对哦)
我们再来从安全的角度出发来打标签,比如IP画像,我们会标注IP是不是代理IP
以微信的画像为例,比如,一个微信只登录手机版、不登录其他腾讯的业务、不聊天、频繁的加好友、被好友删除、朋友圈要么没开通、要么开通了朋友圈但是评论多但回复少,这种号码我们一般会标注微信养号(色情、营销),类似的我们也会给微信打上其他标签。
标签的类别和明细,需要做风控的人自己去设定,比如:地理位置,按省份标记。性别,按男女标记。其他细致规则以此规律自己去设定。
我们看看腾讯的IP画像,沉淀的逻辑如下:
一般的业务都有针对IP的频率、次数限制的策略,那么黑产为了对抗,必然会大量采用代理IP来绕过限制。
既然代理IP的识别如此重要,那我们就以代理IP为例来谈下腾讯识别代理IP的过程。
识别一个IP是不是代理IP,技术不外乎就是如下四种:
反向探测技术:扫描IP是不是开通了80,8080等代理服务器经常开通的端口,显然一个普通的用户IP不太可能开通如上的端口。
HTTP头部的X_Forwarded_For:开通了HTTP代理的IP可以通过此法来识别是不是代理IP;如果带有XFF信息,该IP是代理IP无疑。
Keep-alive报文:如果带有Proxy-Connection的Keep-alive报文,该IP毫无疑问是代理IP。
查看IP上端口:如果一个IP有的端口大于10000,那么该IP大多也存在问题,普通的家庭IP开这么大的端口几乎是不可能的。
以上代理IP检测的方法几乎都是公开的,但是盲目去扫描全网的IP,被拦截不说,效率也是一个很大的问题。
除了利用网络爬虫爬取代理IP外,还利用如下办法来加快代理IP的收集:通过业务建模,收集恶意IP(黑产使用代理IP的可能性比较大)然后再通过协议扫描的方式来判断这些IP是不是代理IP。每天腾讯都能发现千万级别的恶意IP,其中大部分还是代理IP。
5年迭代5次,抖音推荐系统演进历程
2021 年,字节跳动旗下产品总 MAU 已超过 19 亿。在以抖音、今日头条、西瓜视频等为代表的产品业务背景下,强大的推荐系统显得尤为重要。Flink 提供了非常强大的 SQL 模块和有状态计算模块。目前在字节推荐场景,实时简单计数特征、窗口计数特征、序列特征已经完全迁移到 Flink SQL 方案上。结合 Flink SQL 和 Flink 有状态计算能力,我们正在构建下一代通用的基础特征计算统一架构,期望可以高效支持常用有状态、无状态基础特征的生产。
业务背景
对于今日头条、抖音、西瓜视频等字节跳动旗下产品,基于 Feed 流和短时效的推荐是核心业务场景。而推荐系统最基础的燃料是特征,高效生产基础特征对业务推荐系统的迭代至关重要。
主要业务场景

- 抖音、火山短视频等为代表的短视频应用推荐场景,例如 Feed 流推荐、关注、社交、同城等各个场景,整体在国内大概有 6 亿 + 规模 DAU;
- 头条、西瓜等为代表的 Feed 信息流推荐场景,例如 Feed 流、关注、子频道等各个场景,整体在国内有数亿规模 DAU;业务痛点和挑战

目前字节跳动推荐场景基础特征的生产现状是“百花齐放”。离线特征计算的基本模式都是通过消费 Kafka、BMQ、Hive、HDFS、Abase、RPC 等数据源,基于 Spark、Flink 计算引擎实现特征的计算,而后把特征的结果写入在线、离线存储。各种不同类型的基础特征计算散落在不同的服务中,缺乏业务抽象,带来了较大的运维成本和稳定性问题。
而更重要的是,缺乏统一的基础特征生产平台,使业务特征开发迭代速度和维护存在诸多不便。如业务方需自行维护大量离线任务、特征生产链路缺乏监控、无法满足不断发展的业务需求等。

在字节的业务规模下,构建统一的实时特征生产系统面临着较大挑战,主要来自四个方面:
巨大的业务规模:抖音、头条、西瓜、火山等产品的数据规模可达到日均 PB 级别。例如在抖音场景下,晚高峰 Feed 播放量达数百万 QPS,客户端上报用户行为数据高达数千万 IOPS。 业务方期望在任何时候,特征任务都可以做到不断流、消费没有 lag 等,这就要求特征生产具备非常高的稳定性。
较高的特征实时化要求:在以直播、电商、短视频为代表的推荐场景下,为保证推荐效果,实时特征离线生产的时效性需实现常态稳定于分钟级别。
更好的扩展性和灵活性:随着业务场景不断复杂,特征需求更为灵活多变。从统计、序列、属性类型的特征生产,到需要灵活支持窗口特征、多维特征等,业务方需要特征中台能够支持逐渐衍生而来的新特征类型和需求。
业务迭代速度快:特征中台提供的面向业务的 DSL 需要足够场景,特征生产链路尽量让业务少写代码,底层的计算引擎、存储引擎对业务完全透明,彻底释放业务计算、存储选型、调优的负担,彻底实现实时基础特征的规模化生产,不断提升特征生产力;
迭代演进过程
在字节业务爆发式增长的过程中,为了满足各式各样的业务特征的需求,推荐场景衍生出了众多特征服务。这些服务在特定的业务场景和历史条件下较好支持了业务快速发展,大体的历程如下:
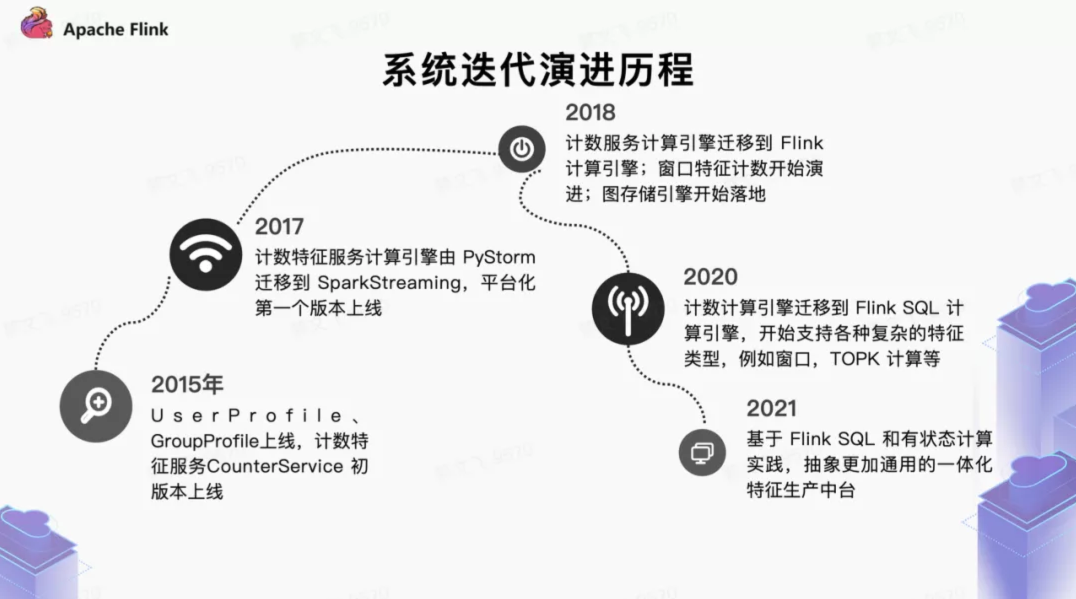
推荐场景特征服务演进历程
在这其中 2020 年初是一个重要节点,我们开始在特征生产中引入 Flink SQL、Flink State 技术体系,逐步在计数特征系统、模型训练的样本拼接、窗口特征等场景进行落地,探索出新一代特征生产方案的思路。
新一代系统架构
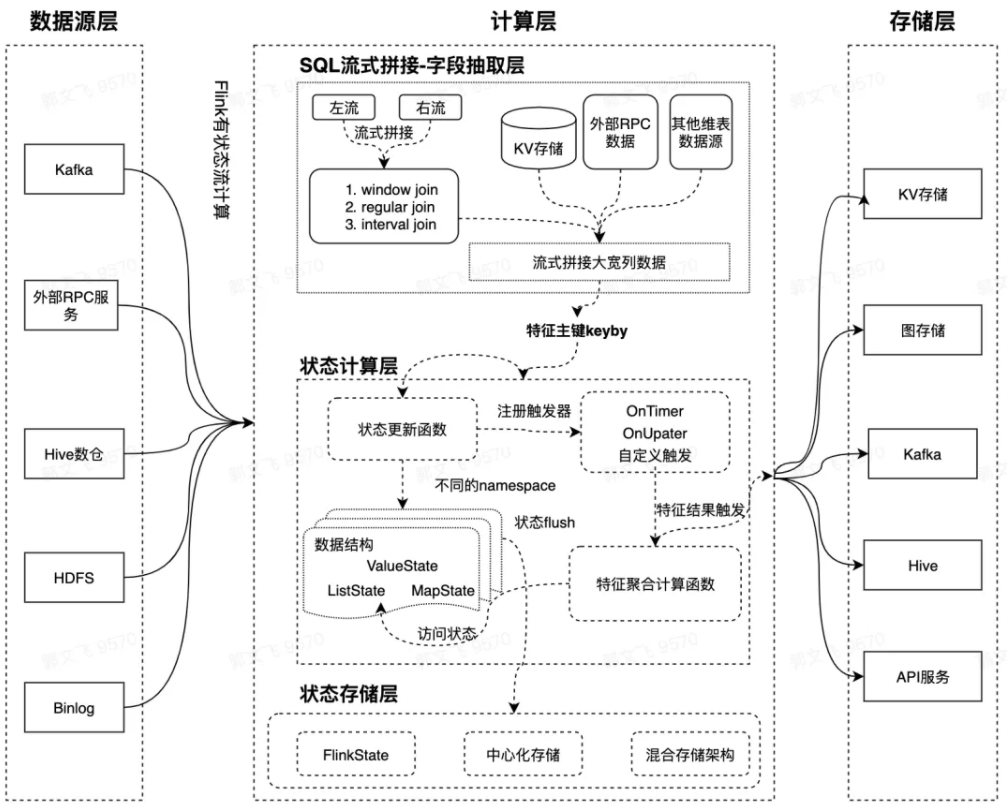
结合上述业务背景,我们基于 Flink SQL 和 Flink 有状态计算能力重新设计了新一代实时特征计算方案。新方案的定位是:解决基础特征的计算和在线 Serving,提供更加抽象的基础特征业务层 DSL。 在计算层,我们基于 Flink SQL 灵活的数据处理表达能力,以及 Flink State 状态存储和计算能力等技术,支持各种复杂的窗口计算。极大地缩短业务基础特征的生产周期,提升特征产出链路的稳定性。新的架构里,我们将 特征生产的链路分为数据源抽取 / 拼接、状态存储、计算三个阶段,Flink SQL 完成特征数据的抽取和流式拼接,Flink State 完成特征计算的中间状态存储。
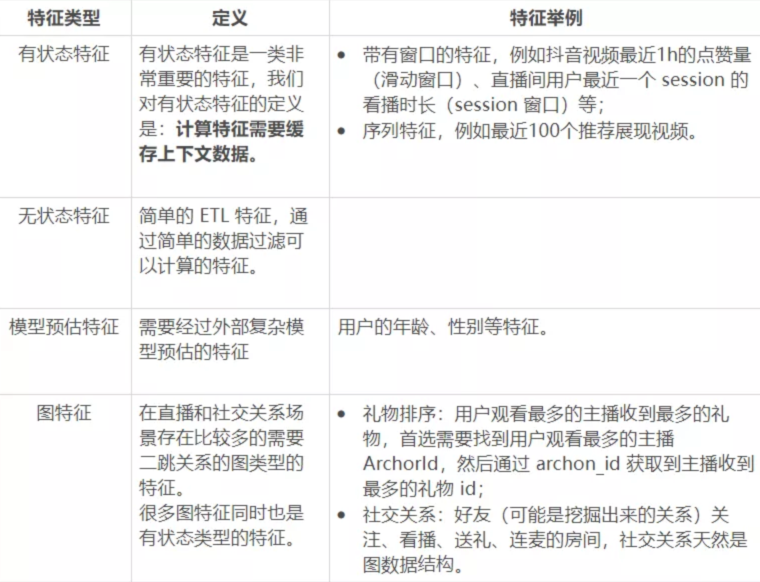
有状态特征是非常重要的一类特征,其中最常用的就是带有各种窗口的特征,例如统计最近 5 分钟视频的播放 VV 等。对于窗口类型的特征在字节内部有一些基于存储引擎的方案,整体思路是“轻离线重在线”,即把窗口状态存储、特征聚合计算全部放在存储层和在线完成。离线数据流负责基本数据过滤和写入,离线明细数据按照时间切分聚合存储(类似于 micro batch),底层的存储大部分是 KV 存储、或者专门优化的存储引擎,在线层完成复杂的窗口聚合计算逻辑,每个请求来了之后在线层拉取存储层的明细数据做聚合计算。
我们新的解决思路是“轻在线重离线”,即把比较重的 时间切片明细数据 状态存储和窗口聚合计算全部放在离线层。窗口结果聚合通过 离线窗口触发机制 完成,把特征结果 推到 在线 KV 存储。在线模块非常轻量级,只负责简单的在线 serving,极大地简化了在线层的架构复杂度。在离线状态存储层。我们主要依赖 Flink 提供的 原生状态存储引擎 RocksDB,充分利用离线计算集群本地的 SSD 磁盘资源,极大减轻在线 KV 存储的资源压力。
对于长窗口的特征(7 天以上窗口特征),由于涉及 Flink 状态层明细数据的回溯过程,Flink Embedded 状态存储引擎没有提供特别好的外部数据回灌机制(或者说不适合做)。因此对于这种“状态冷启动”场景,我们引入了中心化存储作为底层状态存储层的存储介质,整体是 Hybrid 架构。例如 7 天以内的状态存储在本地 SSD,7~30 天状态存储到中心化的存储引擎,离线数据回溯可以非常方便的写入中心化存储。
除窗口特征外,这套机制同样适用于其他类型的有状态特征(如序列类型的特征)。
实时特征分类体系
整体架构
带有窗口的特征,例如抖音视频最近 1h 的点赞量(滑动窗口)、直播间用户最近一个 session 的看播时长(session 窗口)等;
数据源层
在新的一体化特征架构中,我们统一把各种类型数据源抽象为 Schema Table,这是因为底层依赖的 Flink SQL 计算引擎层对数据源提供了非常友好的 Table Format 抽象。在推荐场景,依赖的数据源非常多样,每个特征上游依赖一个或者多个数据源。数据源可以是 Kafka、RMQ、KV 存储、RPC 服务。对于多个数据源,支持数据源流式、批式拼接,拼接类型包括 Window Join 和基于 key 粒度的 Window Union Join,维表 Join 支持 Abase、RPC、HIVE 等。具体每种类型的拼接逻辑如下:

三种类型的 Join 和 Union 可以组合使用,实现复杂的多数据流拼接。例如 (A union B) Window Join (C Lookup Join D)。

另外,Flink SQL 支持复杂字段的计算能力,也就是业务方可以基于数据源定义的 TableSchema 基础字段实现扩展字段的计算。业务计算逻辑本质是一个 UDF,我们会提供 UDF API 接口给业务方,然后上传 JAR 到特征后台加载。另外对于比较简单的计算逻辑,后台也支持通过提交简单的 Python 代码实现多语言计算。
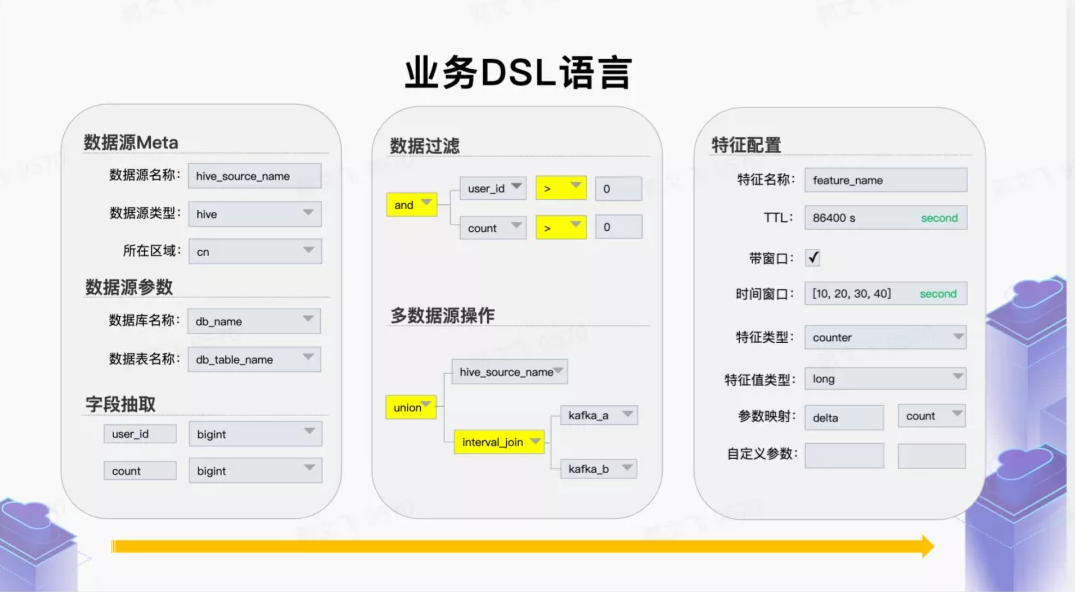
业务 DSL
从业务视角提供高度抽象的特征生产 DSL 语言,屏蔽底层计算、存储引擎细节,让业务方聚焦于业务特征定义。业务 DSL 层提供:数据来源、数据格式、数据抽取逻辑、数据生成特征类型、数据输出方式等。
状态存储层
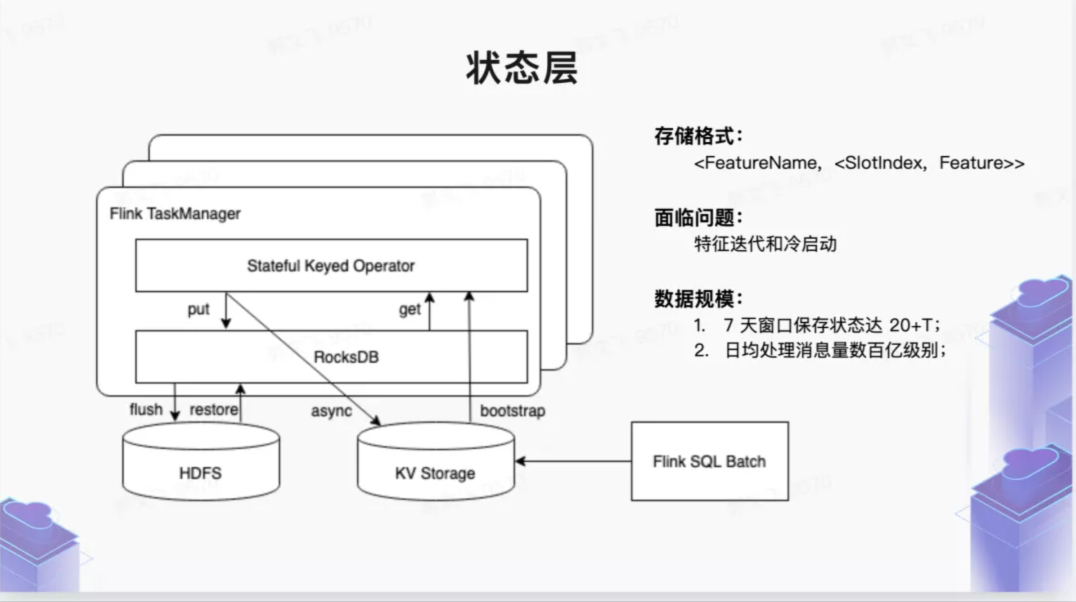
如上文所述,新的特征一体化方案解决的主要痛点是:如何应对各种类型(一般是滑动窗口)有状态特征的计算问题。对于这类特征,在离线计算层架构里会有一个状态存储层,把抽取层提取的 RawFeature 按照切片 Slot 存储起来 (切片可以是时间切片、也可以是 Session 切片等)。切片类型在内部是一个接口类型,在架构上可以根据业务需求自行扩展。状态里面其实存储的不是原始 RawFeature(存储原始的行为数据太浪费存储空间),而是转化为 FeaturePayload 的一种 POJO 结构,这个结构里面支持了常见的各种数据结构类型:
- Int:存储简单的计数值类型 (多维度 counter);
- HashMap<int, int>:存储二维计数值,例如 Action Counter,key 为 target_id,value 为计数值;
- SortedMap<int, int>: 存储 topk 二维计数 ;
- LinkedList:存储 id_list 类型数据;
- HashMap<int, List>:存储二维 id_list;
- 自定义类型,业务可以根据需求 FeaturePayload 里面自定义数据类型
状态层更新的业务接口:输入是 SQL 抽取 / 拼接层抽取出来的 RawFeature,业务方可以根据业务需求实现 updateFeatureInfo 接口对状态层的更新。对于常用的特征类型内置实现了 update 接口,业务方自定义特征类型可以继承 update 接口实现。
/** * 特征状态 update 接口 */public interface FeatureStateApi extends Serializable { /** * 特征更新接口, 上游每条日志会提取必要字段转换为 fields, 用来更新对应的特征状态 * * @param fields * context: 保存特征名称、主键 和 一些配置参数 ; * oldFeature: 特征之前的状态 * fields: 平台 / 配置文件 中的抽取字段 * @return */FeaturePayLoad assign(Context context,FeaturePayLoad feature, Map<String, Object> rawFeature);}
当然对于无状态的 ETL 特征是不需要状态存储层的。
计算层
特征计算层完成特征计算聚合逻辑,有状态特征计算输入的数据是状态存储层存储的带有切片的 FeaturePayload 对象。简单的 ETL 特征没有状态存储层,输入直接是 SQL 抽取层的数据 RawFeature 对象,具体的接口如下:
/** * 有状态特征计算接口 */public interface FeatureStateApi extends Serializable {
/** * 特征聚合接口,会根据配置的特征计算窗口, 读取窗口内所有特征状态,排序后传入该接口 * * @param featureInfos, 包含 2 个 field * timeslot: 特征状态对应的时间槽 * Feature: 该时间槽的特征状态 * @return */ FeaturePayLoad aggregate(Context context, List<Tuple2<Slot, FeaturePayLoad>> slotStates);
}
有状态特征聚合接口
/** * 无状态特征计算接口 */public interface FeatureConvertApi extends Serializable {
/** * 转换接口, 上游每条日志会提取必要字段转换为 fields, 无状态计算时,转换为内部的 feature 类型 ; * * @param fields * fields: 平台 / 配置文件 中的抽取字段 * @return */ FeaturePayLoad convert(Context context, FeaturePayLoad featureSnapshot, Map<String, Object> rawFeatures);
}
无状态特征计算接口
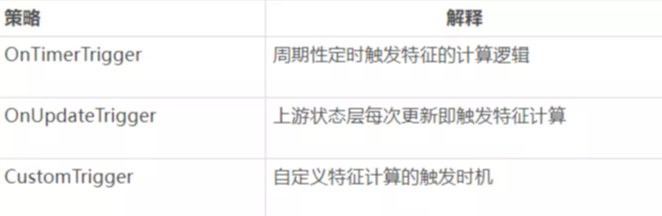
另外通过触发机制来触发特征计算层的执行,目前支持的触发机制主要有:
业务落地
目前在字节推荐场景,新一代特征架构已经在抖音直播、电商、推送、抖音推荐等场景陆续上线了一些实时特征。主要是有状态类型的特征,带有窗口的一维统计类型、二维倒排拉链类型、二维 TOPK 类型、实时 CTR/CVR Rate 类型特征、序列类型特征等。
在业务核心指标达成方面成效显著。在直播场景,依托新特征架构强大的表达能力上线了一批特征之后,业务看播核心指标、互动指标收益非常显著。在电商场景,基于新特征架构上线了 400+ 实时特征。其中在直播电商方面,业务核心 GMV、下单率指标收益显著。在抖音推送场景,基于新特征架构离线状态的存储能力,聚合用户行为数据然后写入下游各路存储,极大地缓解了业务下游数据库的压力,在一些场景中 QPS 可以下降到之前的 10% 左右。此外,抖音推荐 Feed、评论等业务都在基于新特征架构重构原有的特征体系。
值得一提的是,在电商和抖音直播场景,Flink 流式任务状态最大已经达到 60T,而且这个量级还在不断增大。预计不久的将来,单任务的状态有可能会突破 100T,这对架构的稳定性是一个不小的挑战。
性能优化
Flink State Cache
目前 Flink 提供两类 StateBackend:基于 Heap 的 FileSystemStateBackend 和基于 RocksDB 的 RocksDBStateBackend。对于 FileSystemStateBackend,由于数据都在内存中,访问速率很快,没有额外开销。而 RocksDBStateBackend 存在查盘、序列化 / 反序列化等额外开销,CPU 使用量会有明显上升。在字节内部有大量使用 State 的作业,对于大状态作业,通常会使用 RocksDBStateBackend 来管理本地状态数据。RocksDB 是一个 KV 数据库,以 LSM 的形式组织数据,在实际使用的过程中,有以下特点:
- 应用层和 RocksDB 的数据交互是以 Bytes 数组的形式进行,应用层每次访问都需要序列化 / 反序列化;
- 数据以追加的形式不断写入 RocksDB 中,RocksDB 后台会不断进行 compaction 来删除无效数据。
业务方使用 State 的场景多是 get-update,在使用 RocksDB 作为本地状态存储的过程中,出现过以下问题:
- 爬虫数据导致热 key,状态会不断进行更新 (get-update),单 KV 数据达到 5MB,而 RocksDB 追加更新的特点导致后台在不断进行 flush 和 compaction,单 task 出现慢节点(抖音直播场景)。
- 电商场景作业多数为大状态作业 (目前已上线作业状态约 60TB),业务逻辑中会频繁进行 State 操作。在融合 Flink State 过程中发现 CPU 的开销和原有~~ 的~~ 基于内存或 abase 的实现有 40%~80% 的升高。经优化后,CPU 开销主要集中在序列化 / 反序列化的过程中。
针对上述问题,可以通过在内存维护一个对象 Cache,达到优化热点数据访问和降低 CPU 开销的目的。通过上述背景介绍,我们希望能为 StateBackend 提供一个通用的 Cache 功能,通过 Flink StateBackend Cache 功能设计方案达成以下目标:
- 减少 CPU 开销 : 通过对热点数据进行缓存,减少和底层 StateBackend 的交互次数,达到减少序列化 / 反序列化开销的目的。
- 提升 State 吞吐能力 : 通过增加 Cache 后,State 吞吐能力应比原有的 StateBackend 提供的吞吐能力更高。理论上在 Cache 足够大的情况下,吞吐能力应和基于 Heap 的 StateBackend 近似。
- Cache 功能通用化 : 不同的 StateBackend 可以直接适配该 Cache 功能。目前我们主要支持 RocksDB,未来希望可以直接提供给别的 StateBackend 使用,例如 RemoteStateBackend。
经过和字节基础架构 Flink 团队的合作,在实时特征生产升级 ,上线 Cache 大部分场景的 CPU 使用率大概会有高达 50% 左右的收益;
PB IDL 裁剪
在字节内部的实时特征离线生成链路当中,我们主要依赖的数据流是 Kafka。这些 Kafka 都是通过 PB 定义的数据,字段繁多。公司级别的大 Topic 一般会有 100+ 的字段,但大部分的特征生产任务只使用了其中的部分字段。对于 Protobuf 格式的数据源,我们可以完全通过裁剪数据流,mask 一些非必要的字段来节省反序列化的开销。PB 类型的日志,可以直接裁剪 idl,保持必要字段的序号不变,在反序列化的时候会跳过 unknown field 的解析,这 对于 CPU 来说是更节省的,但是网络带宽不会有收益, 预计裁剪后能节省非常多的 CPU 资源。在上线了 PB IDL 裁剪之后,大部分任务的 CPU 收益在 30% 左右。
遇到的问题
新架构特征生产任务本质就是一个有状态的 Flink 任务,底层的状态存储 StateBackend 主要是本地的 RocksDB。主要面临两个比较难解的问题,一是任务 DAG 变化 Checkpoint 失效,二是本地存储不能很好地支持特征状态历史数据回溯。
- 实时特征任务不能动态添加新的特征:对于一个线上的 Flink 实时特征生产任务,我们不能随意添加新的特征。这是由于引入新的特征会导致 Flink 任务计算的 DAG 发生改变,从而导致 Flink 任务的 Checkpoint 无法恢复,这对实时有状态特征生产任务来说是不能接受的。目前我们的解法是禁止更改线上部署的特征任务配置,但这也就导致了线上生成的特征是不能随便下线的。对于这个问题暂时没有找到更好的解决办法,后期仍需不断探索。
- 特征状态冷启动问题:目前主要的状态存储引擎是 RocksDB,不能很好地支持状态数据的回溯。后续规划
当前新一代架构还在字节推荐场景中快速演进,目前已较好解决了实时窗口特征的生产问题。
出于实现统一推荐场景下特征生产的目的,我们后续会继续基于 Flink SQL 流批一体能力,在批式特征生产发力。此外也会基于 Hudi 数据湖技术,完成特征的实时入湖,高效支持模型训练场景离线特征回溯痛点。规则引擎方向,计划继续探索 CEP,推动在电商场景有更多落地实践。在实时窗口计算方向,将继续深入调研 Flink 原生窗口机制,以期解决目前方案面临的窗口特征数据退场问题。
- 支持批式特征:这套特征生产方案主要是解决实时有状态特征的问题,而目前字节离线场景下还有大量批式特征是通过 Spark SQL 任务生产的。后续我们也会基于 Flink SQL 流批一体的计算能力,提供对批式场景特征的统一支持,目前也初步有了几个场景的落地;
- 特征离线入湖:基于 Hudi On Flink 支持实时特征的离线数仓建设,主要是为了支持模型训练样本拼接场景离线特征回溯;
- Flink CEP 规则引擎支持:Flink SQL 本质上就是一种规则引擎,目前在线上我们把 Flink SQL 作为业务 DSL 过滤语义底层的执行引擎。但 Flink SQL 擅长表达的 ETL 类型的过滤规则,不能表达带有时序类型的规则语义。在直播、电商场景的时序规则需要尝试 Flink CEP 更加复杂的规则引擎。
- Flink Native Windowing 机制引入:对于窗口类型的有状态特征,我们目前采用上文所述的抽象 SlotState 时间切片方案统一进行支持。另外 Flink 本身提供了非常完善的窗口机制,通过 Window Assigner、Window Trigger 等组件可以非常灵活地支持各种窗口语义。因此后续我们也会在窗口特征计算场景引入 Flink 原生的 Windowing 机制,更加灵活地支持窗口特征迭代。
- Flink HybridState Backend 架构:目前在字节的线上场景中,Flink 底层的 StateBackend 默认都是使用 RocksDB 存储引擎。这种内嵌的存储引擎不能通过外部机制去提供状态数据的回灌和多任务共享,因此我们需要支持 KV 中心化存储方案,实现灵活的特征状态回溯。
- 静态属性类型特征统一管理:通过特征平台提供统一的 DSL 语义,统一管理其他外部静态类型的特征服务。例如一些其他业务团队维度的用户分类、标签服务等
吃上抖音红利的核心逻辑内容一定要懂
为什么BAT三座大山拦在前面?抖音的母公司字节跳动还能强势崛起,不管你是企业还是个人,只要你想要吃上抖音上的红利,这条讲解抖音核心逻辑的内容,你一定要看懂。
2012年3月,在北京海淀区志杰这家公司成立了,所有人都觉得在中国做互联网是绕不开BAT的,想要绝地反超,那就更不可能了,在这种情况之下,这家公司却先后推出了今日头条、抖音短视频、懂车帝番茄小说等等爆款产品,它靠的是什么?
团队、产品、技术还是资本都不是,他靠的是和BAT完全不同的世界观,再说一遍,抖音能够强势崛起,依靠的是与BAT完全不同的世界观,什么意思呢?
你看啊,在传统的经典市场营销体系里面,用户的分类方式是按照身份标签来的,性别、年龄、财富、收入,结婚没有,没有小孩多大在哪住,简单来说,就是把人给分成369等,你是住在富人区的土豪还是租住在城中村的普通人,按照这个分类来做出不同的产品卖给不同的人,这就是传统的营销流程,原来都是这么干的,但是效率却非常低,5000块的红酒只推给那些年入百万的人,这直接就放弃了大部分市场,这种分类方式的基本假设是土豪和普通人的兴趣爱好,以及,他们对产品的需求是截然不同的。
他们仿佛生活在两个世界,老死不相重叠,但你思考一下,这一点跟现实严重不符,对吧,字节跳动在做头条的时候,看到了一个秘密,那就是土豪和普通人的兴趣爱好,其实相当一部分是重叠一致的,亿万身价的思聪哥和你一样喜欢去吃深夜的路边摊,也会聊上土耳情话宝儿啊,再有钱的大老板,也可能会像普通人一样拼手速去抢一个几毛钱的小红包,没错,每个人都有自己的身份,但是你的身份并不能准确定义你这个人,以及你真实的兴趣和爱好,你每天都在做那些事儿才可以。
很多互联网巨头都意识到了这一点,所以有个东西叫做千人千面,听说过吧,但是只有字节跳动研究最深,做得最彻底,它是基于兴趣标签和算法呀,弄出了一套全新的用户分类方法,构建了一个全新的世界,在这里人不分369等,只有兴趣偏好之别,你所做的每一个动作都会让算法给你打上一个小标签,慢慢地,每个用户身上都有了成千上万个记号,它们汇集在一起,就构建成了一个算法眼里的人。
这个时候生意该怎么做呢?直接把这瓶5000块的红酒推给喜欢他的人就够了,既精准又不会丢失掉潜在用户,这种更加精准的用户分类也带来了更高的广告营销效率、更高的广告营销效率自然带来了更多的广告组合收益,这很重要,但是事情远没有到此截止,顶尖的兴趣算法还让内容的推送逻辑成为了现实,比如在头条里,用户看到的都是自己关心的。而不是像其他平台由主编给你编排好顺序的内容,你只能选择被动接受,所以,这才有了今日头条的slogan,你关心的才是头条。
基于兴趣算法的内容推送逻辑有什么厉害之处,传统的微信微博,他们的传播是关注逻辑的,在这些平台上,你作为一个作者发布内容之后,只有关注你的人才能够看得到他喜欢的内容,才有可能分享出去,分享出去之后,你才有可能得到新的粉丝,这种情况之下,你就得挖空心思去讨好粉丝。
但是在抖音呢,没人能知道,谁可以看到自己的视频,你在抖音推荐上刷到的内容也大多不是你关注的账号,你想要讨好都无从下手,就像我不知道屏幕前的你是谁,所以你的身份、财富、地位都不重要,重要的是你的内容而已,决定你流量的也只是你的内容而已,这就是为什么我说企业和普通人一定要来做抖音,因为只有在这里,你才能和那些土豪高管站在同一条起跑线上。
这世界每隔一段时间都会被创新者重构一次,方式有所不同,但基本逻辑是相同的,产品技术从来都只是表象,更重要的是你的世界观怎么看待这个世界,这个世界就会怎样回报你
一文搞懂抖音、视频号、知乎、小红书的算法机制
抖音、小红书、知乎、视频号是很多品牌必争的流量洼地。
掌握几个平台的流量算法,可以让我们尽可能获取更多的流量,今天就来给大家分享一下四个平台的算法机制。
1. 抖音
抖音的流量算法几乎是所有流量平台中最为复杂的,当然也是流量最大的。
抖音是典型的“标签”对“标签”的平台。
如果你是用户,平台会根据你平时的浏览喜好把你的关注点拆解成大约150个标签,你能刷到哪些视频一定程度上是你的用户标签决定的。如果浏览喜好发生变化,用户标签也会随之变化,刷到的视频也会跟着标签而变化。
如果你是创作者,平台会根据你发布的内容形成创作者标签,标签数量同样是150个,如果发布内容产生变化,创作者标签也会随之变化。
创作者发布视频后,视频会根据创作者标签匹配相似的用户标签,这就是上面我们讲过的“标签”对“标签”的流量算法。
短视频匹配到用户后,会通过该视频的数据表现来衡量该视频是否值得进一步的推荐。
抖音对单个视频的推荐,会考核5个关键数据:
1)完播率
完播率=观看时间/作品时间
完播率越高,说明作品越吸引人观看,大盘的合格线通常是15%-20%左右,40%-50%以上的完播率就已经很优秀了。要想办法做高完播率,通常的方式是开头设置悬念或者引导打开评论区,拉长观看时间。
如果是新号的话,建议前期视频时长不要太长,时长越长,完播越低,除非视频质量极佳。
2)点赞率
点赞率=点赞量/播放量
点赞量越高,推荐量才会越高,第一波推荐的点赞率至少要达到3%-5%,也就是说每100个播放量,至少要有3-5个点赞。
3)留言率
留言率=留言量/播放量
留言率的数据高低跟视频类型有很大关系,不好用平均数据去衡量,但确定的是留言率表现越好,加权推荐就越高。所以,创作者可以主动在视频中或者文案、评论区引导评论,提升留言率,
4)转发率
转发率=转发量/播放量
转发率对于还在初级流量池流传的视频影响并不大,但想要突破流量层级,转发率就是很关键的指标。
5)转粉率
转粉率=关注量/播放量
也就是路转粉的比例,单条视频带来的新增粉丝率,同样是冲击高级流量池的关键数据。
抖音平台是一个巨大的流量池,抖音推荐机制是一个渔网,视频内容是鱼饵。
如果你的视频的五个关键数据都能取得较好的数据表现,那么进入到中高级的流量池继续流转的可能性非常大。
抖音的流量池也有它的法则。
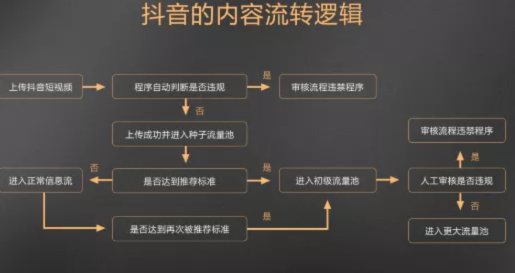
视频发布后会进入冷启动池,流量通常是是300-500,一般是由粉丝+朋友+可能认识的人+少量标签匹配的用户构成,因为冷启动池的流量构成最为复杂,也是最难突破的流量池,这就要考验,你的粉丝是否精准,内容是够优质,如果关键数据达标会进入到初级流量池。
初级流量池的流量大约在1000-5000左右,同样需要继续观察视频在初级流量池的变现,如果数据继续过关,将进入中级流量池。
中级流量池就有10000以上的播放量,同理看数据表现;
高级流量池就有十万+以上的播放量了,上不封顶。
2. 小红书
小红书的算法和抖音类似,也是“标签”对“标签”的流量算法。
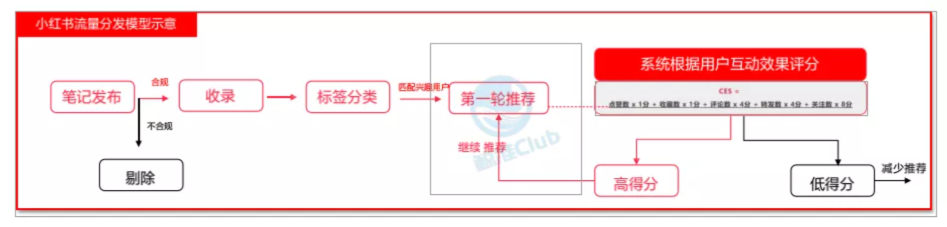
不同的是,基于不同的用户习惯,抖音更侧重主动推荐,小红书更侧重搜索推荐。
基于小红书的平台定位,超过65%的流量来源于搜索,所以在搜索流量算法上更精细一些,所以这里侧重讲一下搜索流量算法的逻辑。
搜索结果与需求的匹配主要是核心关键词与query的匹配度,搜索结果中展示的具体内容是通过分析用户需求,找到最能命中用户需求的信息。
一篇笔记标题中的关键词可谓是重中之重,官方也明确提示:“填写标题会有更多赞哦”。
由此可见,标题是小红书官方用来识别内容属性的重要选项,想要让笔记获得更多的展现,最基础的工作就是要做好标题的优化。
我们要善用搜索的关键词、热词推荐等来帮助我们找到笔记核心词,以便能让系统识别并推荐给对应用户。
1)从推荐内容找核心词
推荐内容包括几个方面,搜索框置灰关键词,页面显示的历史搜索,热搜词
01. 默认提示词
点开搜索还未输入搜索词之前,平台会根据用户标签推荐默认提示词,默认提示词中存在一定量的搜索流量
02. 搜索发现(热门搜索)
热门搜索把最近一段时间被搜索次数最多的词展示出来,去引导用户看一些最近热门的内容和用户搜索量大的话题推荐,跟用户的搜素量和近期的热门话题相关
03. 补充联想关键词
补充联想关键词,即用户输入部分内容,然后系统根据这些内容联想出完整内容,自动补全关键词,通过即时匹配关键词并展示出来,增加用户的选择。我搜了显瘦,平台就给我推荐了关于显瘦的几个关键词推荐
考虑热词排序是综合展示的结果。除了笔记数外,“热词” 的热度排序可能还牵涉到两个方面的因素:用户主动搜索的频率,以及笔记本身被系统推荐的热度
搜索之后,系统根据搜索词进行算法匹配,把所有结果都展示出来。而如果这个关键词是相关品类中范围比较大的词汇,那么就能看到在界面上半部分有一些专门的标签词汇提供分类筛选的功能。
这种方式对于用户无目的搜索的体验会更好。同时将最热门的笔记排在前面,这种搜索结果的展示形式以及筛选条件,目的都是为了缩小选择范围,帮助用户快速选择
2)关于关键词的选择有以下几点值得注意:
01. 小红书的热搜推荐是平台短期流量内容的标识;搜索提示关键词、筛选热门是长期流量所在,来源于小红书真实的用户数据分析和总结;
02. 一定要优先选择竞争度小流量大且比较精准的关键词,避免选择宽泛的关键词;
03. 学会反推关键词。确定笔记主题及关键词后,要去反推希望用户用什么关键词能搜到自己的笔记,考虑如果自己去搜这类笔记会用哪些常见关键词去搜;
04. 在笔记标题、正文、话题、评论等位置合理的布局关键词,有助于笔记被收录及精准推荐。避免堆砌关键词,堆砌关键词会被系统判定为广告,长期这样操作,账号会被系统降权。
3. 知乎
首先是针对搜索流量,知乎的搜索排名其实跟搜索引擎是有类似的,内容需要先进行收录,然后才能提升搜索词排名。
1)看内容和搜索关键词的匹配度
匹配度越高,收录的概率也就越大;另一方面,优质账号的权重更高,能够获得的搜索词排名也会更高;最后,内容的热度也会影响搜索排名,总之越热门的内容排名会更加靠前。
当然,搜索还涉及到问题下回答的排名,一般来说,搜索词收录该问题后,会抓取问题下其中一条高赞的回答展现,除此之外,因为用户的习惯一般会参考不止一条回答,那么该问题下自然排序第一的回答,也有更大的曝光概率。
所以,如果能够实现搜索词+问题下的排名都非常靠前,那么流量自然就会更好;如果不能实现两者均很靠前,那么起码要实现有一条在靠前的位置。
2)关注推荐流量
推荐流量是通过知乎的推荐算法,然后将内容推送给用户。
一般来说,推荐算法会先将内容推送给一小部分人,然后收集反馈数据,如阅读完成率、赞同率、互动数据等,来判断这条内容是否值得持续推荐。
3)关注热榜流量
热榜是知乎的全站实时热门内容合集,其维度主要是看24小时的浏览量、互动量和领域权重来计算。
想要内容上热榜,那就必须要在短时间内有大量的领域内用户参与互动,形成不错的声量后,内容自然热度就提升上去了。
当然,针对视频类内容,其分发机制跟推荐类似,而且有单独的榜单支撑,参考即可。
4)关注综合算法
和头条、抖音等平台不同的是,知乎采用的是威尔逊算法,即根据内容的点赞、反对、收藏等数据,按照威尔逊公式来决定内容的推荐和排名。
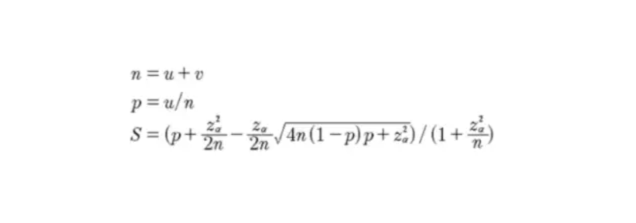
u代表内容的赞同数,v代表内容的反对数,p则代表内容的赞同率=赞同数/(赞同+反对),而Z则是与权重相关的数字
算法公式虽然很复杂,但大家只需要记住最核心的一点:赞同率比赞同数重要,反对率比赞同率重要
和其他内容平台不相同的是,除了点赞和互动,知乎用户还可以给不同意的内容点反对票,而反对票数一定程度上将会影响回答排名
4. 视频号
微信视频号和其他流量平台的算法完全不同,视频号的分发机制是基于社交推荐和个性化推荐
1)社交推荐
社交是微信生态的先天基因,所以对于微信视频号来讲,社交关系链同样非常重要,比如你的好友发布和点赞的内容,会优先推荐。一个作品,你的好友点赞收藏互动多的话,你的阅读量曝光量就会上升,相反,如果非好友进行点赞收藏的话,对于你作品的曝光低于好友点赞收藏
所以,你微信好友的点赞收藏互动对于作品提升权重有很大的影响
其实这个就跟公众号的“在看”和“点赞“的逻辑相似,比如你给某个文章(视频)点了“在看”,你好友将会在微信“看一看”刷到这个文章(视频),你好友点赞了,他的好友也可能会刷到这个作品,以此类推
2)个性化推荐
指的是系统会根据用户的日常行为、活动轨迹和兴趣、职业、年龄等标签,通过一系列大数据算法,推测出用户可能喜欢的内容。因为微信本身就拥有11亿的超级用户画像和各种算法机制作为参考
不过目前由于微信视频号尚处于热启动阶段,目前数据库并不全面,采用的数据源都是从微信大盘抓取,算法基本会采用兴趣标签+定位+热点+随机推荐
所以无论是发视频还是发图片,添加话题和定位更有助于个性化推荐。这一点跟抖音的推荐算法有点相似,只不过目前还不够成熟
3)去中心化的推荐算法
视频号虽然是基于社交推荐,但每个人的社交关系链毕竟有限,当一个作品已经在完整的社交关系链获得了展现且取得了较好的数据表现后,视频号会进行社交关系链以外的扩大推荐,逻辑类似于抖音的“标签”对“标签”,这里不做过多延展
以上就是抖音、小红书、知乎、视频号的流量算法,相信大家仔细阅读后会对四大平台有新的了解和认识。
